Realme.govt.nz and Capital Surveillance
Posted by vonnagy on Mar 04 2020
Realme is an NZ government project sponsored by the New Zealand government. While the initiative deserves credit, it has fallen short protections for complete privacy.
In short, Realme.govt.nz doesn’t track your online habits, but by using Google’s doubleclick and Google Fonts, it provides your online habits to Google and make you more track-able. This may look innocuous at first, especially since they openly state that they use analytics and it does not collect private information. This is the standard notice that Google provides all their clients, regardless if they are government or private business.
Why does this matter, after Realme is being transparent in there terms and conditions?
The problem is not that Realme isn’t transparent; it is that Google trackers are opaque. At best RealMe acting as a proxy for Google advertisers; at worst RealMe may lending its credentials to verify data for Google advertisers.
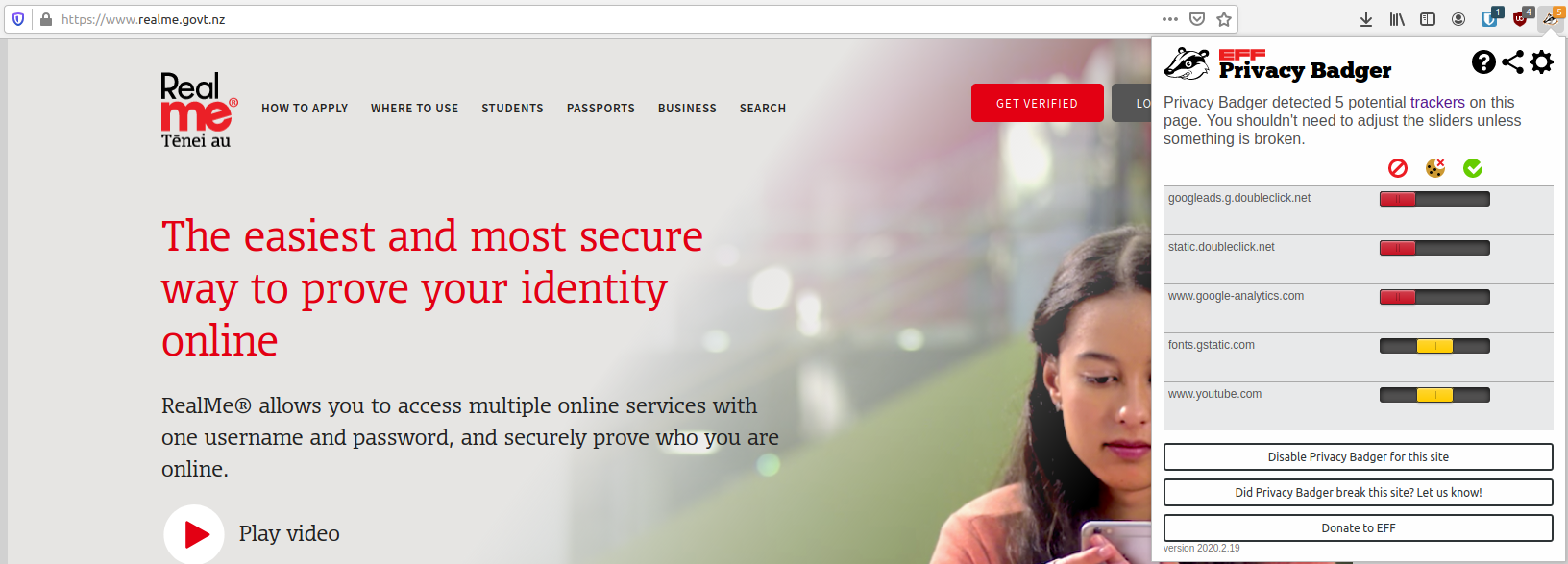
Let’s have a look at specifically how three of these trackers on RealMe websites works:
fonts.gstatic.com tracker
This is a popular font for ensuring consistent design. These fonts are hosting on Google’s remote server. Fonts are essential harmless themselves, however they can be used for what is known as dark patterns: a ploy used by an app or website to engage users in behaviours that they do wish to engage in.
How can simple web hosted fonts do this?
First of all, as soon as visitor loads the RealMe site which renders a Google font, numerous data can be collected such as, but not limited to IP, location, and device. This is no different than using a tracking pixel or javascript tracking. Any remotely embedded web object can be used for tracking.
Google specifically states in their terms and conditions:
YOU AGREE THAT GOOGLE MAY MONITOR USE OF THE APIS TO ENSURE QUALITY, IMPROVE GOOGLE PRODUCTS AND SERVICES, AND VERIFY YOUR COMPLIANCE WITH THE TERMS
What are Google products and services? Google makes 70% of their income from ad services. It would be naive to think that Google would not use fonts in conjunction with their advertising purposes.
static.Doubleclick.net tracker
This is Google’s advertising tracking. Doubleclick was the advertising company that Google purchased in 2007. This tracker watches your online behavour and use to align advertising to previous actions. For instance, if it sees you log to register for a passport, it can use this sell travel advertising.
There is no need to for this be on the RealMe website; it serves no purpose. Here is information on the static.doubleclick.net tracker may
- the time and date you saw an advert.
- the unique ID number the cookie has given your browser
- unique ID of the advert
- the ID of where the advert was seen on the site
- what page you were on when you saw the advert
- IP Address (which can guess your location)
Keep in mind none of this is in vacuum; your information is used in conjunction with all sites that have used the this advertising tracker to build a profile.
www.google-analytics. com
This is by an far the most ubiquitous tracker on the internet. As quoted in the research paper “Internet Jones and the Raiders of the Lost Trackers”:
Among trackers with the “most power to capture profiles of user behavior across many sites,” google-analytics.com is cited as a “remarkable outlier,” gathering more data from more sites than any other entity does.
Below is a screenshot from analytics account from there demo account. Note that nothing here is personally identifiable is packaged to the marketers who use this, however Google holds all the data which can be traced. This shows information that can be traced by IP address:
In Europe the user’s IP is to be anonymsied to further protect user’s identity:
The use of Google Analytics without the extension “anonymizeIP” constitutes a violation of data protection law and of the general right of personality. This was decided by the disctrict court („Landgericht“) Dresden in a remarkable judgement of January 11, 2019, which concerns the current data protection discussion on the use of web tracking technology (District court Dresden, judgement of January 1, 2019, reference number 1a O 1582/18).
It’s a very simple process to anonymous the IP in Google analytics, and currently RealMe.govt.nz does not do this, this is the tracking code from the RealMe website as 11 March 2020.
(function(i,s,o,g,r,a,m){i['GoogleAnalyticsObject']=r;i[r]=i[r]||function(){
(i[r].q=i[r].q||[]).push(arguments)},i[r].l=1*new Date();a=s.createElement(o),
m=s.getElementsByTagName(o)[0];a.async=1;a.src=g;m.parentNode.insertBefore(a,m)
})(window,document,'script','//www.google-analytics.com/analytics.js','ga');
ga('create', 'UA-31182395-1', 'auto');
ga('send', 'pageview');
To anonymous this it needs to add this line;
ga('set', 'anonymizeIP', true);
While is no New Zealand law that will hold RealMe accountable to anonymising IP addresses for this marketing tool, it should be this very site that should set a precedent for our privacy.
To make matters worse, by use of the previously mentioned dark patterns, the marketing site Nacho Analytics used Google analytics platform to display scraped user data: It is believed that Nacho Analytics collected browser extensions in conjunction with Google analytics to obtain very sensitive data*:
The issue with Nacho Analytics is that the tool showed third-parties all URLs users visited — and a subset of those URLs led to non-password-protected pages a regular user browsing the internet wouldn’t be able to find.
(Think: things like order confirmation pages, private PDF attachments, and other pages intended for that specific user’s eyes that sometimes aren’t protected by a login screen, but instead, are “blocked” by a set of “tokens” or a series of characters that would be difficult to guess.) Since Nacho Analytics captured and published these pages, users could go directly to the page and sometimes even view the information on it.
This breach exposed everything from flight itineraries, personal emails, and even tax records. While Google analytics itself was not directly responsible for the leak, it was the distribution system for which users could collect and disseminated the data.
What does it mean for the average New Zealander?
Google has essentially hit the jackpot for the tiny New Zealand demographic. More than half a million New Zealanders have a RealMe ID, Google now has a government verified demographic that it can used for advertisers. For a media company this is the gold standard, simply for the credibility that Realme has built up over the years.
Further, more Kiwis are savvier about being tracked, which renders Google analytics useless. The future of digital surveillance will unlikely come through 3rd party tracking tools, but built directly into browsers and apps. Also there is no need for Google fonts, as safe fonts for the web have long been established. In the case of RealMe, safety should be a precedent over design attributes.
One could easily use blockers (such as Privacy Badger in my screenshot) but why should New Zealanders have to be concerned on privacy based site like RealMe?
This does not a recommendation against Realme. If you use this service, you have to upload your personal information – the very act of monitoring this by a 3rd party, outside of NZ jurisdictions, should make one wary.
We can do better.
Read more:
- Google Fonts Terms and Conditions
- A privacy concern about Google Fonts
- Dark Patterns
- Crashlytics Font Tracking
- What is a tracking pixel?
- 620,000 users registered on RealMe
- Understanding digital fingerprinting.
- DoubleClick (Google): What is it and what does it do?
- Shoshanna Zubuff: Age of Capital Surveillance
- My browser, the spy: How extensions slurped up browsing histories from 4M users
* I used Nacho Analytics for a period of about 4 months. I was pretty shocked at the information I could obtain from a competitor’s site, and it left me scratching my head to how they did it. To Google’s credit they deactivated many Nacho Analytic accounts:
Asked if the arrangement violates any of Google’s terms of service, a company representative wrote: “Passing data that personally identifies an individual, such as email addresses or mobile numbers, through Google Analytics is prohibited by our terms of service, and we take action on any account found doing so intentionally.” The representative also said that Google has suspended multiple Google Analytics properties owned by Nacho Analytics for violating Google terms of service. Google employees continue to investigate additional accounts that may be connected or integrated with Nacho Analytics, the representative said, on condition the person not be named or quoted.
It is in the realm of possibility, though highly unlikely, that Realme.govt.nz was affected. I learned about Nacho Analytics during my stay in North America. If there was an issue, its likely that Realme.govt.nz’s Googles representative would have contacted them last year when this unfolded.